DynamoDBについて
2021年11月10日

こんばんは、大学4年生の松井です。 先日、大学4年生の私たちは他の研究室と合同で中間発表というものを行いました。コロナも大分落ち着き久しぶりにあの様なことができてとても楽しかったです。
さて、私は卒業研究に向けていろいろなものを触っているのですが、今回はその中の一つであるDynamoDBについて紹介したいと思います。
DynamoDBとはその名の通りデータベースの一種でAWSの一つです。
AWSといえばクラウドサービスの大御所の一つですが、DynamoDBはローカルでも動かすことができます(同一ネットワークに存在する他端末からのアクセスも可能)。ローカルで使う際には費用はかからず実際に私はデータを蓄積するという目的だけでなくローカルネットワークに存在する端末間のデータの通信や保存などもDynamoDBで行なっています。
DynamoDBの大きな特徴としては処理の速さとデータの構造があります。
処理の速さについて本来は他データベースと比較検証するべきなのですが、そこには至れていません、すみません。
データの構造についてはKVS(key-value store)と呼ばれるもので以下の様になっています。
 この一つがデータになっていてこれらが大量に集まることでテーブルを構成しており、また、一つのデータには
”名前”: {
"型": "値"
}
のような感じで値が保持されています。辞書型の配列に近い感じです。型についてはN(umber)が数値、S(tring)が文字列、M(ap)はその中にさらに値を複数個保持できます。
図で整理すとこんな感じ、(多分、
この一つがデータになっていてこれらが大量に集まることでテーブルを構成しており、また、一つのデータには
”名前”: {
"型": "値"
}
のような感じで値が保持されています。辞書型の配列に近い感じです。型についてはN(umber)が数値、S(tring)が文字列、M(ap)はその中にさらに値を複数個保持できます。
図で整理すとこんな感じ、(多分、
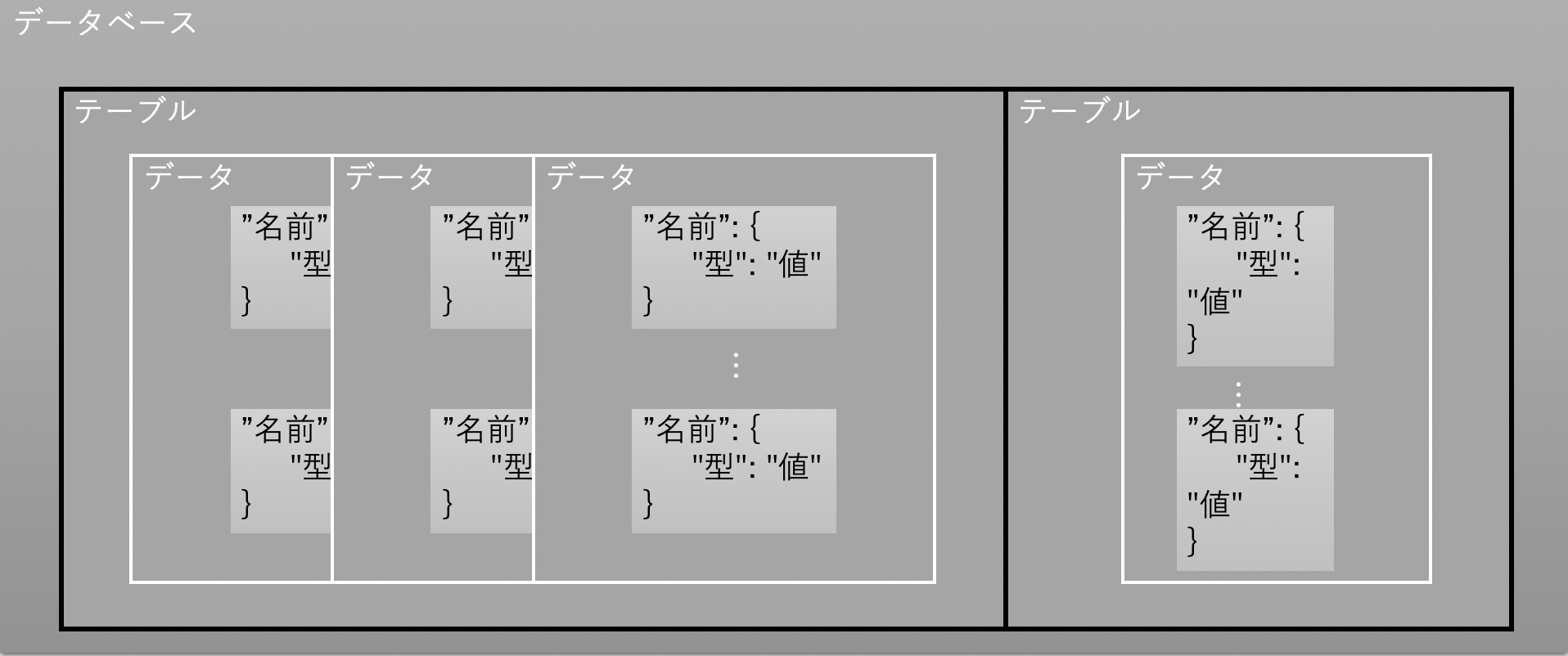 データについては最初にテーブルを作るときに絶対に必要な値(主キーという)を決めるのですが、その主キーさえあれば他の値を複数追加できます。上記の例では"seatNumber"がそれに当たり、新しいデータをテーブルに入れるときには絶対必要です。逆に言うと"whichSensor"や"position"はなくても良いですし"position"ではなく"X","Y"という名前で追加することもできます。テーブルごとに主キーを決めるので他のテーブルで全く違った構造のものを同時に作り上げていけます。この自由度の高さゆえの欠点としてデータの検索やテーブル同士の連結などは苦手としています。
ということでDynamoDBについて簡単にですが紹介させていただきました。いろんな言語で使えて大体書き方は一緒ですので慣れてしまえば結構応用は効くかと思いますので興味があれば是非使って見てください。
データについては最初にテーブルを作るときに絶対に必要な値(主キーという)を決めるのですが、その主キーさえあれば他の値を複数追加できます。上記の例では"seatNumber"がそれに当たり、新しいデータをテーブルに入れるときには絶対必要です。逆に言うと"whichSensor"や"position"はなくても良いですし"position"ではなく"X","Y"という名前で追加することもできます。テーブルごとに主キーを決めるので他のテーブルで全く違った構造のものを同時に作り上げていけます。この自由度の高さゆえの欠点としてデータの検索やテーブル同士の連結などは苦手としています。
ということでDynamoDBについて簡単にですが紹介させていただきました。いろんな言語で使えて大体書き方は一緒ですので慣れてしまえば結構応用は効くかと思いますので興味があれば是非使って見てください。