三年ゼミの発表に向けて
2024年01月30日
3年の曽田です。
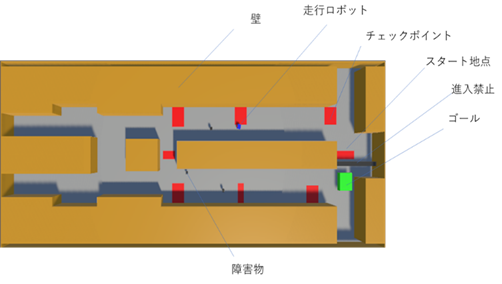
僕は、3年ゼミでロボットの強化学習を実施しています。
明治大学中野校舎11号館の11階通路を実施環境とし、シミュレータとしてUnity、機械学習の環境を構築するためのフレームワークとしてUnity ML-Agentsを採用しました。強化学習のアルゴリズムとしてはPolicy-basedの手法の中で比較的実装が容易で拡張性のあるPPO(Proximal Policy Optimization)を用いています。目的の重みづけ、報酬の与え方を微調整しながらロボットの強化学習を行い、障害物を回避しながら目的地まで自動走行するよりよい方策の獲得を目指しその内容を検証しました。現在、結果をまとめており、2月のゼミ合宿で研究発表します。
その後、スノボに初挑戦します。