深層強化学習による人間を追従しながら目的地へ到達する行動モデルの獲得 その2
2024年05月27日
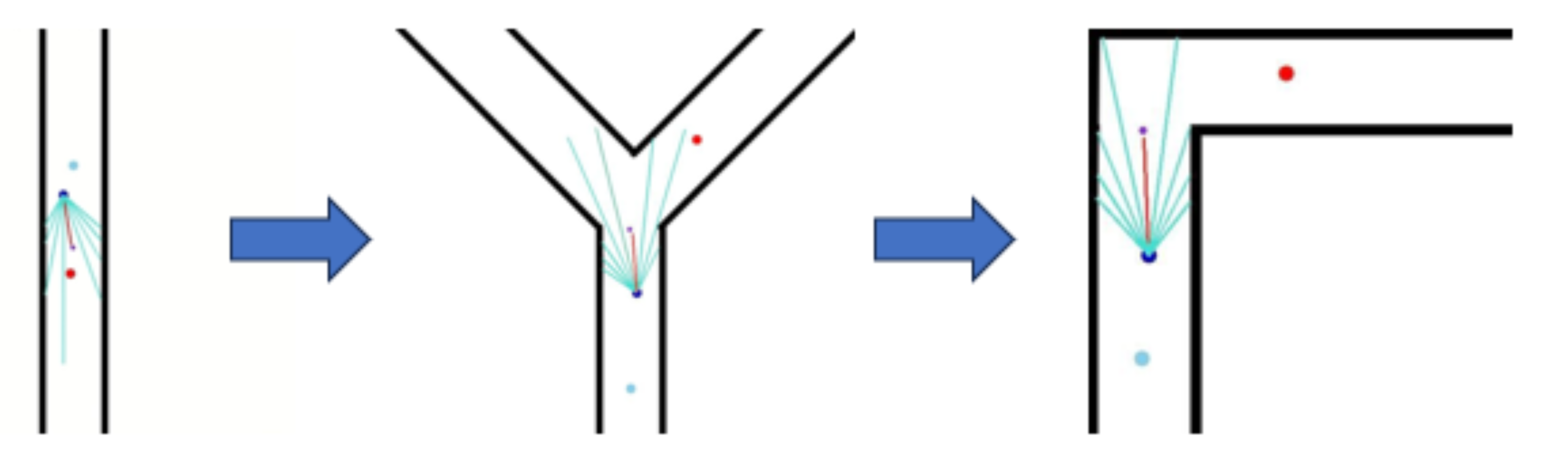
こんにちは。M1の落合です。 前回同様に、深層強化学習による行動モデルの獲得について紹介したいと思います。
前回の直線の環境での学習によって獲得した行動モデルを、緩やかな曲がり角がある環境、急な曲がり角がある環境と 徐々に目的地への到達の難易度が高くなるようにカリキュラム学習を用いて強化学習を行いました。 これらの学習により獲得した行動モデルが緩やかな曲がり角がある環境と急な曲がり角がある環境それぞれにおいて走行可能であるかをシミュレータ環境上で走行実験を行いました。 学習の時と同じ条件でスタート位置、ゴール位置、人間の位置などを変えずに100回走行させました。
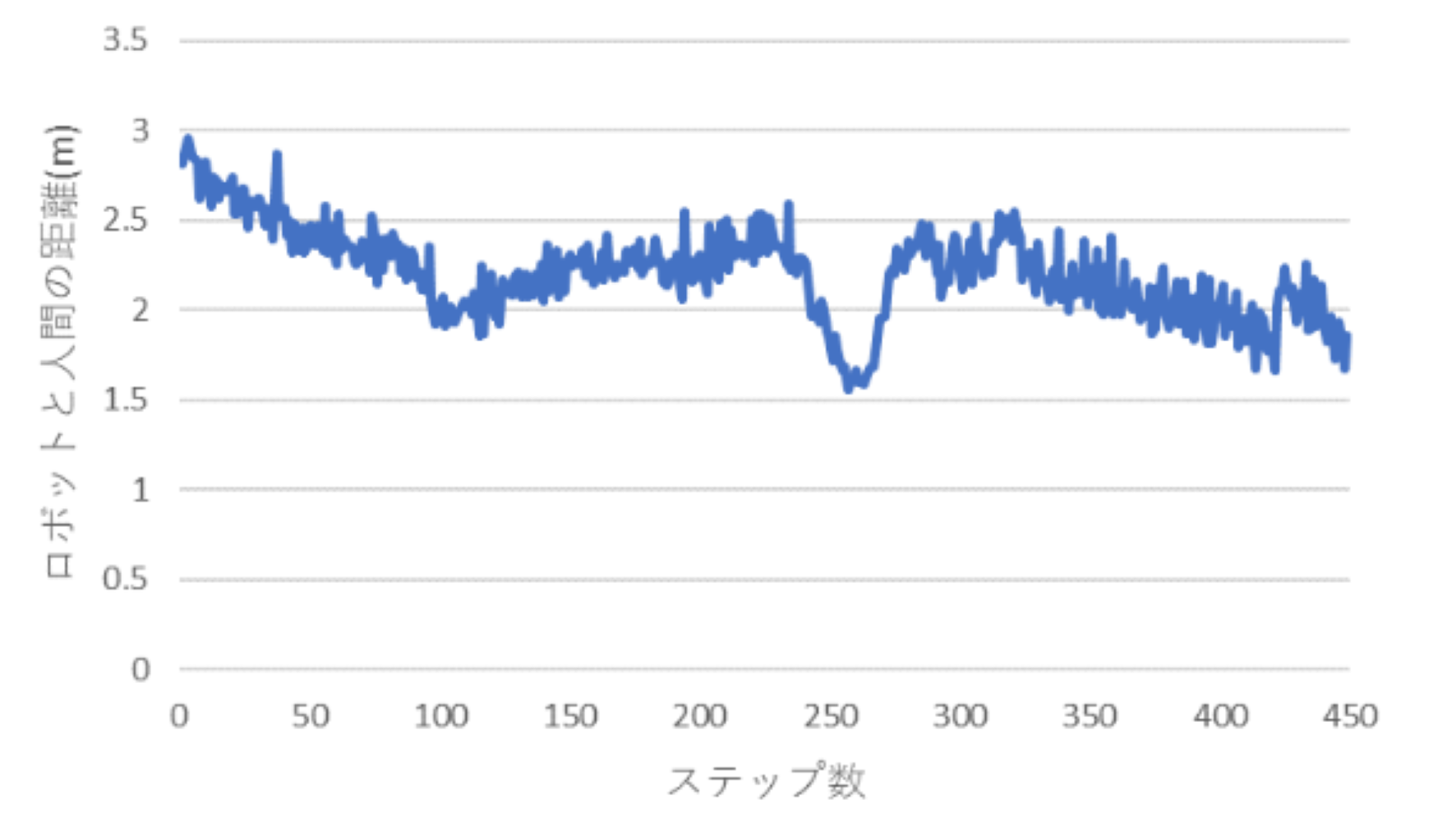
緩やかな曲がり角がある環境においては100回とも人間を追従しながら目的地へ到達することが出来ていました。 下図は、緩やかな曲がり角がある環境で100回走行させたうちのあるエピソードでのロボットと人間の距離の推移を表しています。
次に、急な曲がり角がある環境においては100回中83回人間を追従しながら目的地へ到達することが出来ていました。 目的地へ到達できなかった17回はすべて人間を見つけることが出来ずに障害物に衝突してしまっていました。 人間と衝突することは一度もなかったのでそれなりに良い結果が得られたと思っています。 下図は、急な曲がり角がある環境でのロボットと人間の距離の推移を表しています。
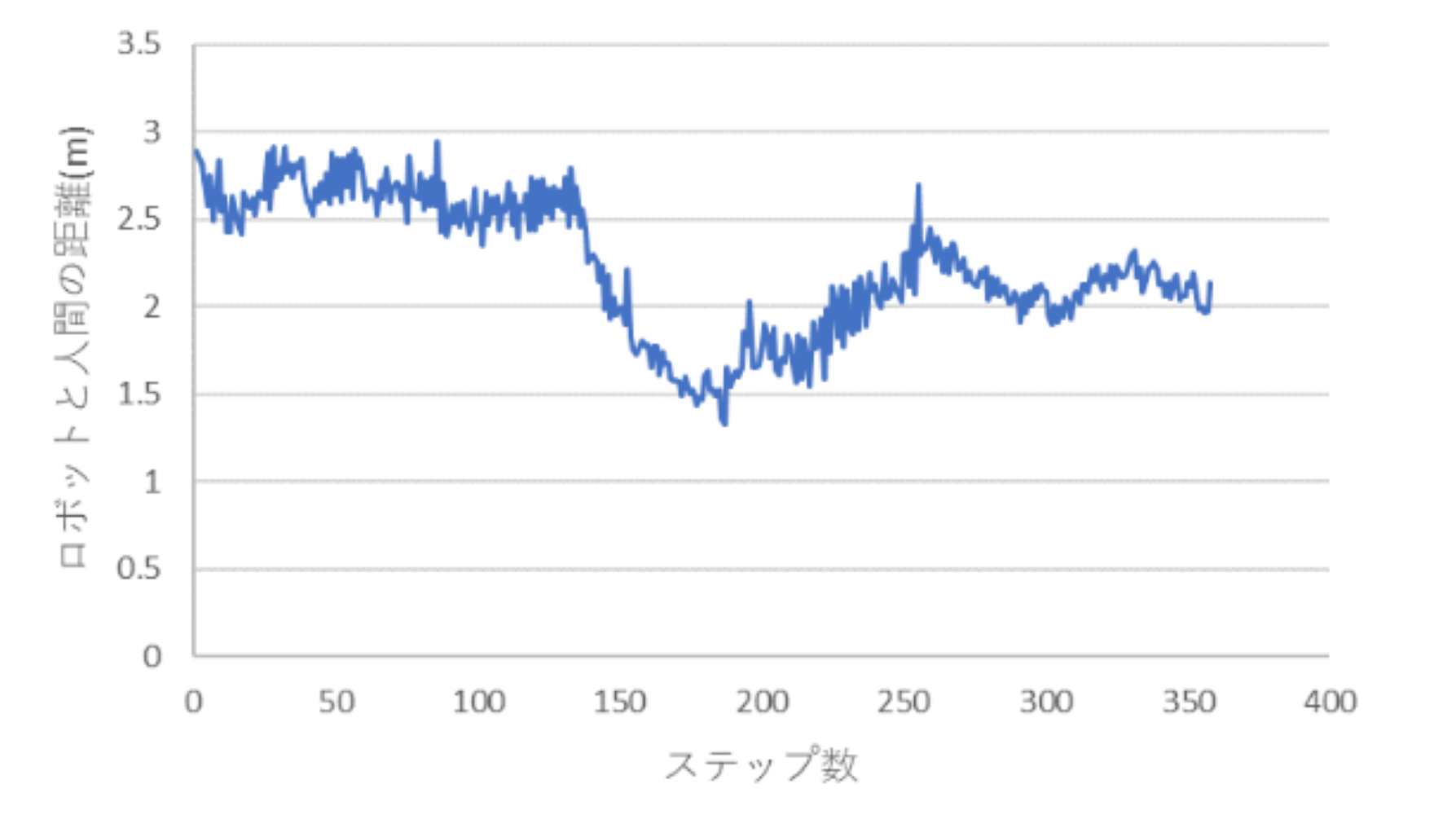
2つの環境でロボットと人間の距離が1.5m~3.0mを保つように走行できました。 また、曲がり角を曲がるとき人間を見失わないように走行するため、一時的にロボットと人間の距離が縮まっています。