研究内容紹介①
2024年11月28日

こんにちは。B4の三品和樹です。 今回の更新では、自身の研究内容を前半と後半に分けて紹介したいと思います。 研究テーマは、「逆強化学習とデモデータの自動収集に基づく移動ロボットの行動モデル獲得」です。 この研究テーマのポイントは、「逆強化学習に用いるデモデータの自動記録」、「逆強化学習によって獲得した行動モデルを適用した実機走行」の2点であり、新規性ともいえます。そこで前半ではデモの自動記録について、後半では逆強化学習による行動モデルの獲得について紹介したいと思います。

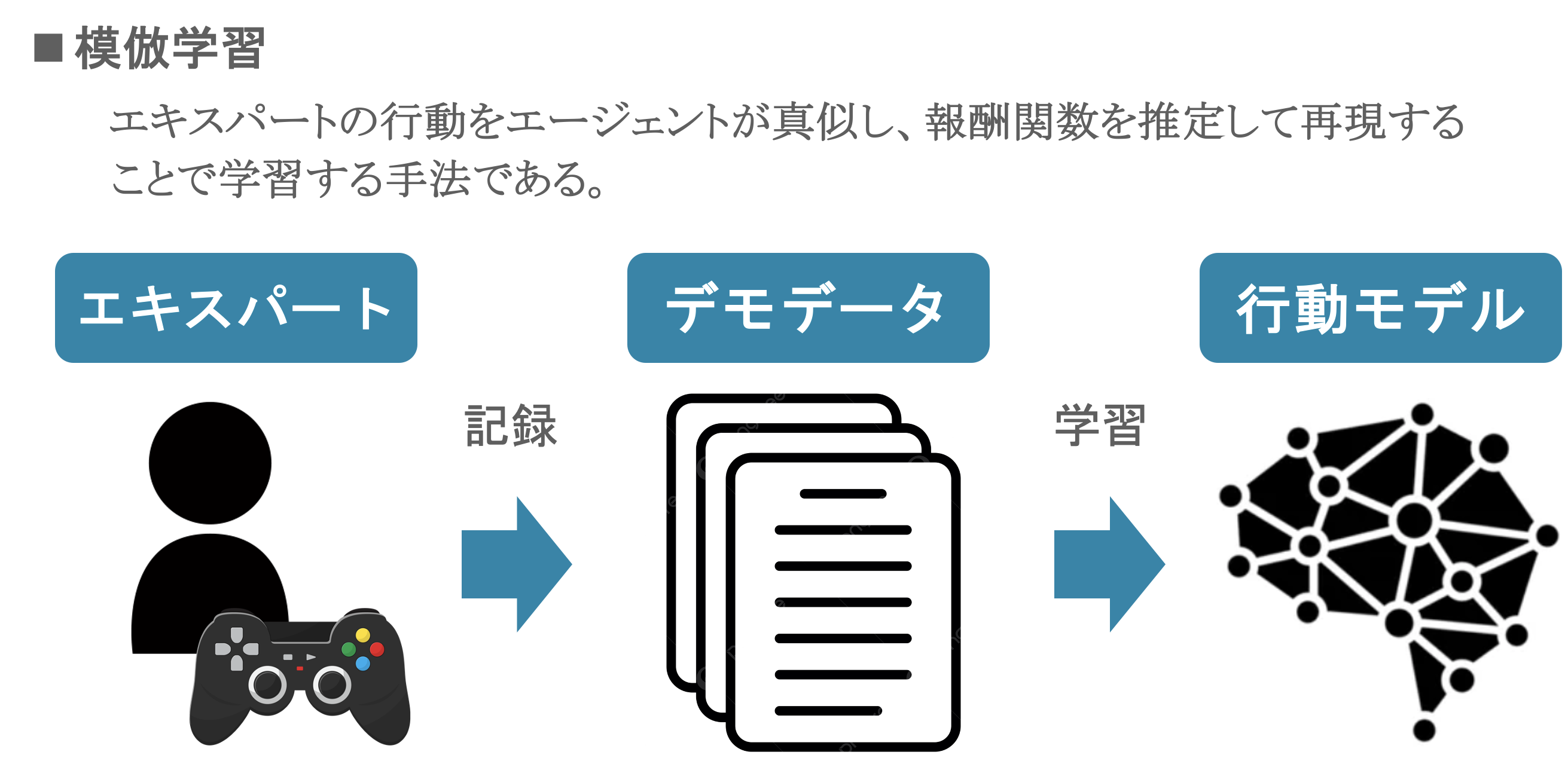
まず、今回の学習手法である逆強化学習について簡単に説明したいと思います。順強化学習では、エージェントが報酬関数を最大化するように行動するのに対し、逆強化学習は、エキスパートがとった行動とそれによる結果を記録し、エージェントがその行動に着目することで報酬関数自体を推定する学習方法となります。本研究では逆強化学習の一種で、専門家の行動をエージェントが模倣し、報酬関数を推定して再現することで学習する模倣学習という手法を採用しています。逆強化学習には、「複雑な報酬設計が不要」、「学習の効率化」、「類似した他タスクへの転移が容易」といった利点がある一方、「デモデータの記録に手間がかかる」、「専門家の行動が必ずしも最適ではない」といった課題もあります。中でも、デモデータに関しては、多くの研究で手動で記録されており、複雑な環境ほど手間と時間を要するといった問題があります。
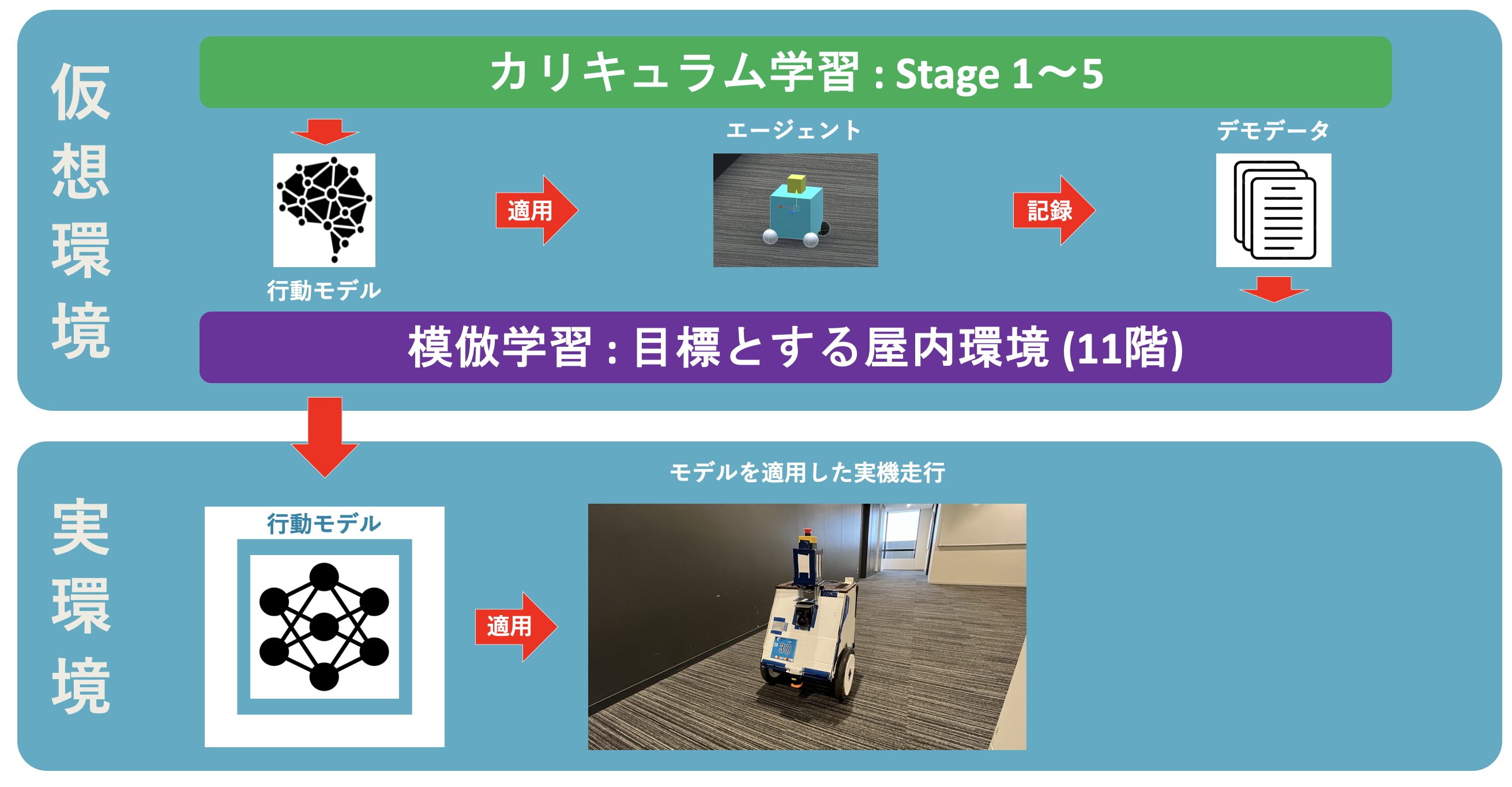
そこで本研究では、屋内環境において基本的な走行性能を有した既存の行動モデルを用いたデモデータの自動記録を提案しました。具体的には、カリキュラム学習により5つの環境を段階的に学習していくことで、屋内環境における基本的な走行知能を持った汎用的な行動モデルを獲得します。ここで生成された行動モデルをエージェントに適用し、仮想環境内で走行させることで、人間の手を介在しないデモデータの自動記録が実現できます。
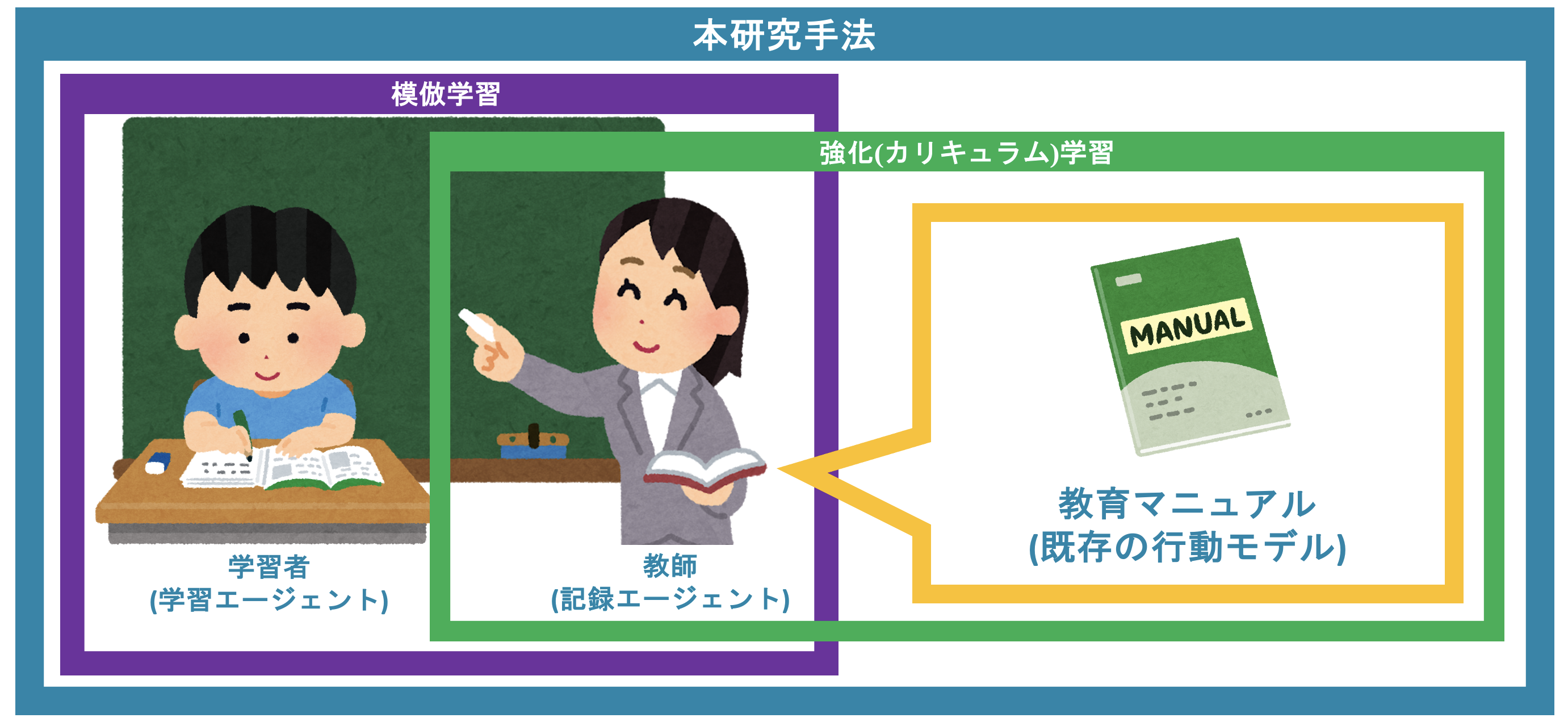
説明だけではわかりにくく、いまいちだと思われる方がいらっしゃると思うので、教育分野に置き換えて学習プロセスを紹介したいと思います。まず、カリキュラム学習によって得られる行動モデルは、教育マニュアルや指導方針書にあたります。その教育マニュアル(基本走行性能)を用いて目標とする環境にて教師がお手本となる行動をして、その行動を記録します。その行動記録を基に学習者が模倣学習を行い、より走行性能を向上させていこうという話になります。難しいですよね。
現段階では、このようなデモの自動記録方法を採用していますが、将来的には環境の自動生成や自律走行によって自動記録を大量に行えればと思っています。以上で前半を終えたいと思います。ご覧いただきありがとうございます!