研究内容紹介②
2024年11月28日

こんにちは。B4の三品和樹です。 前回の更新に引き続き自身の研究内容について紹介したいと思います。 今回はこの研究のもう1つのポイントである、「逆強化学習によって獲得した行動モデルを適用した実機走行」について紹介したいと思います。

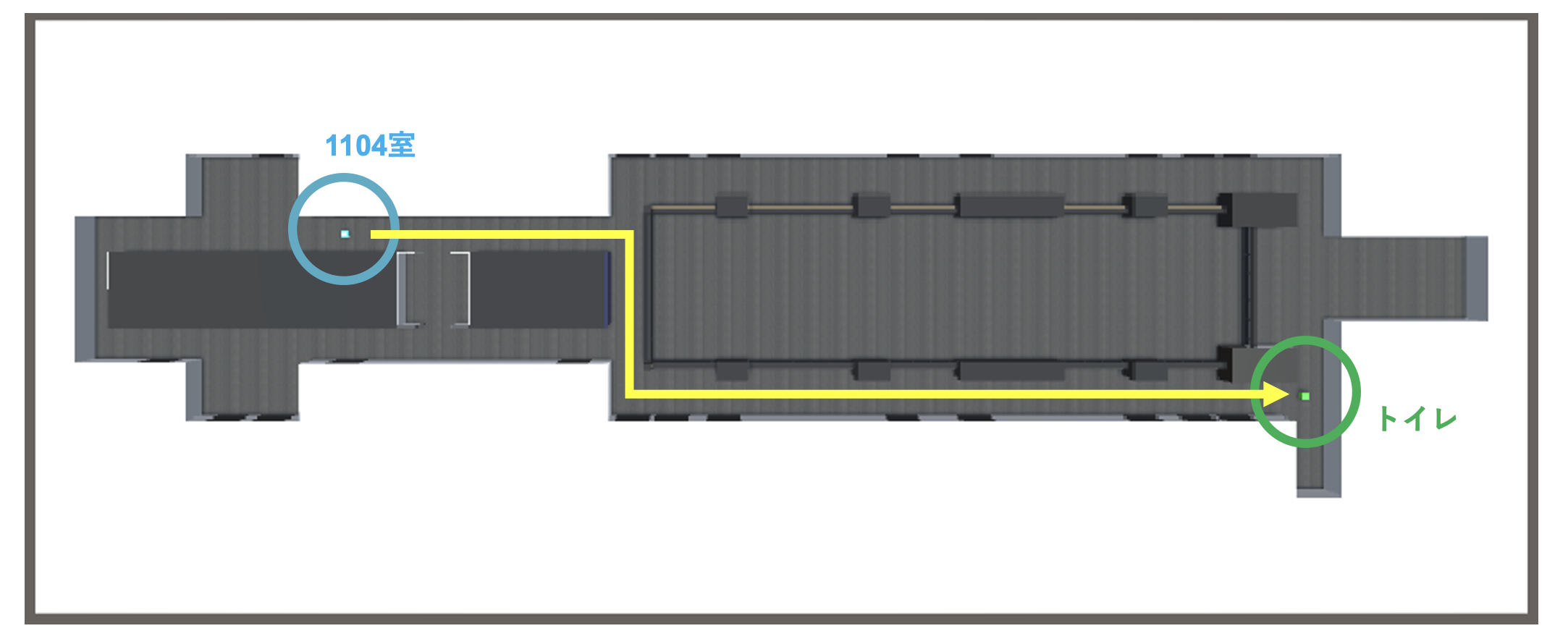
前回お話ししたように本研究では逆強化学習の一種であるも模倣学習を用いています。学習環境については、ゲーム開発エンジンのUnityで明治大学11階を再現しています。この環境内で図の経路のように、自身の研究室がある1104室からトイレまでの走行を目指します。模倣学習を行うために必要なデモでデータについては、前回の手法により自動で10エピソード程記録します。その後生成されたデモデータを用いて模倣学習を行うといった感じです。
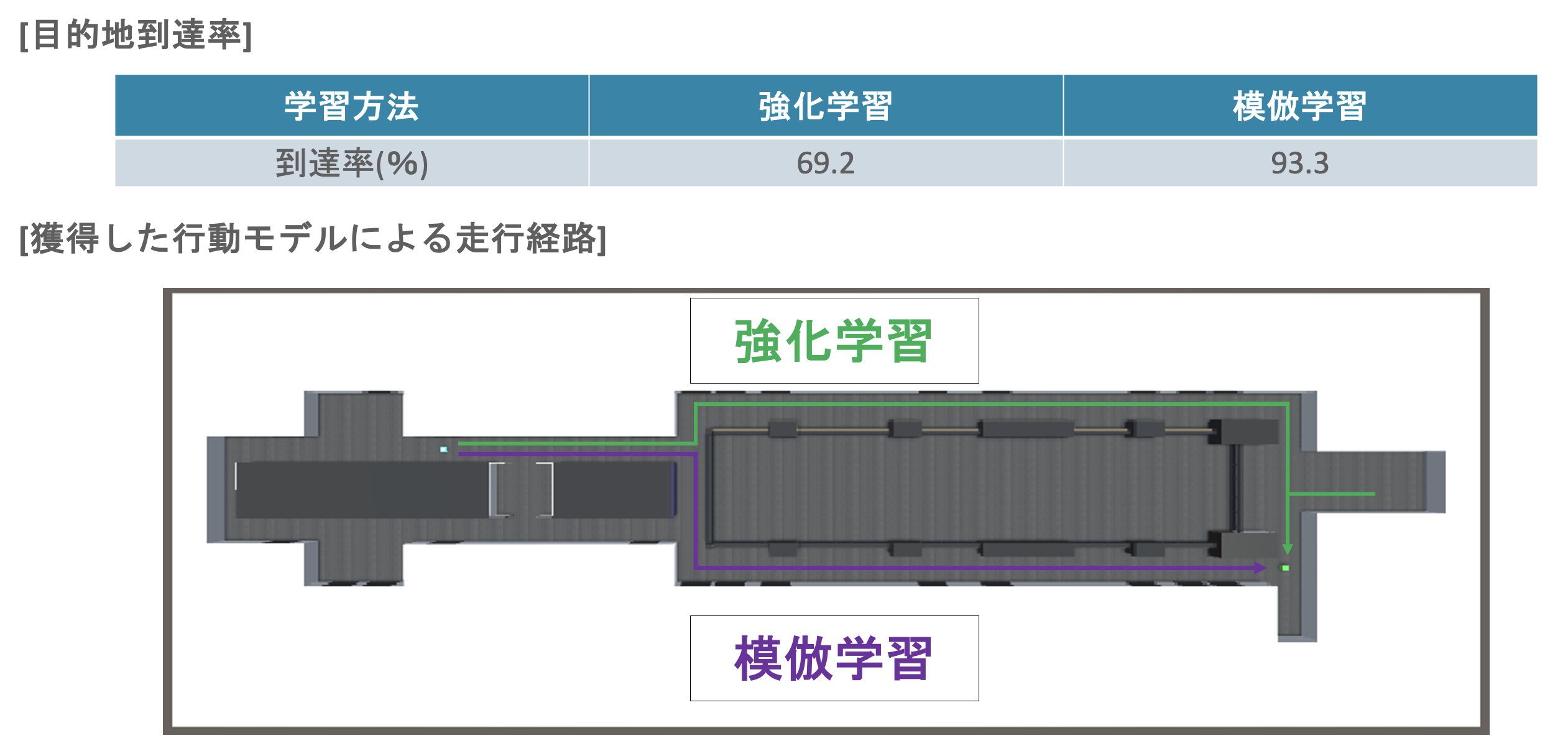
現段階では、今回行った模倣学習が強化学習の学習結果と比較して走行経路及び到達確率の両方で良い性能であるという結果が得られています。なお、「今回の手法は2回学習しているんだから当たり前じゃん!」と思われる方もいらっしゃると思いますが、あくまでも模倣学習の精度はデモデータに依存しており、カリキュラム学習はデモデータの自動記録に用いているだけです。それに加えて、走行環境が変化しても屋内であれば、カリキュラム学習によって得られた行動モデル(基本走行知能)を新たに学習し直す必要なく、デモの記録に用いることができるといった汎用性もあります。
続いてモデルを適用した実機走行についてですが、結果から申しますと、まだ実現できていません。仮想環境内では高い目的地到達率を誇っているため、行動モデルが原因とは考えたくないのですが、壁に衝突する動作が多く見られるのでモデルに問題があるのかもしれません。今後はモデルの性能や実機走行のシステムを見直して、実環境での走行を目指したいと思います。
卒業研究の中間発表も終わり、現状の課題と今後の展望が明確になったので、卒論に向けてより一層精進していきたいと思います!ご覧いただきありがとうございます!