機械学習
2020年08月17日

大学院1年の古谷です。
今回の記事では機械学習の話をしていこうと思います。
機械学習といっても細かく見ていけばかなりの種類のアルゴリズムがあり、さらには現在進行形でどんどん新しいアルゴリズムが開発されています。
私が研究で取り扱っているアルゴリズムは深層強化学習というものでディープニューラルネットワークを用いた機械学習となっています。
詳しい研究内容については以前卒業研究というタイトルで記事を投稿したのでぜひ見てください。
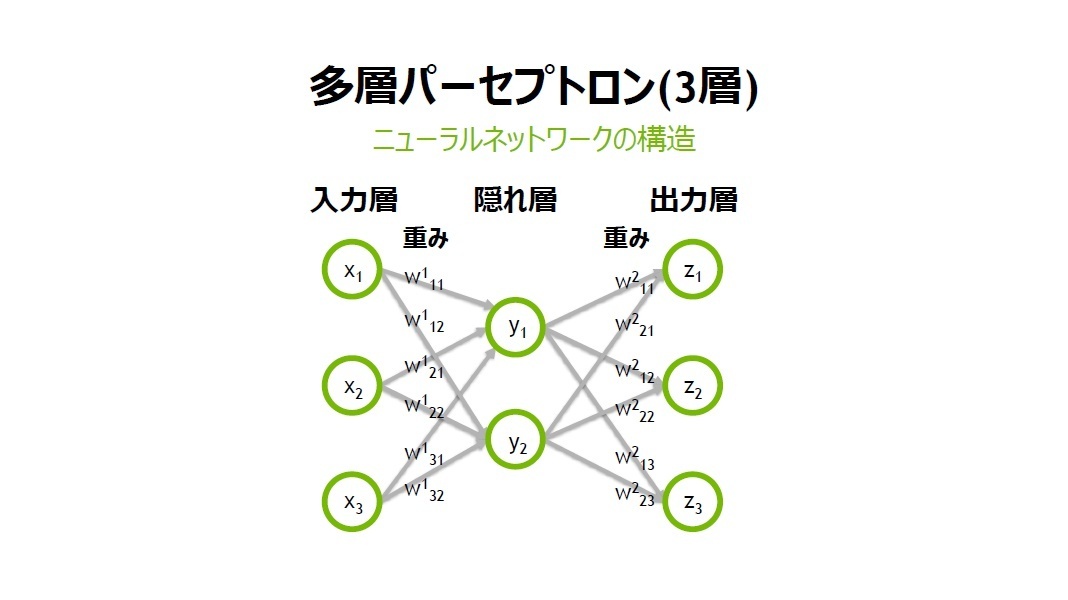 (引用元:https://www.sbbit.jp/article/cont1/33345)
知らない人は多いのですが深層強化学習の中にもさらにアルゴリズムの分類があります。
以下の画像は一部のアルゴリズムマップを表しています。
(引用元:https://www.sbbit.jp/article/cont1/33345)
知らない人は多いのですが深層強化学習の中にもさらにアルゴリズムの分類があります。
以下の画像は一部のアルゴリズムマップを表しています。
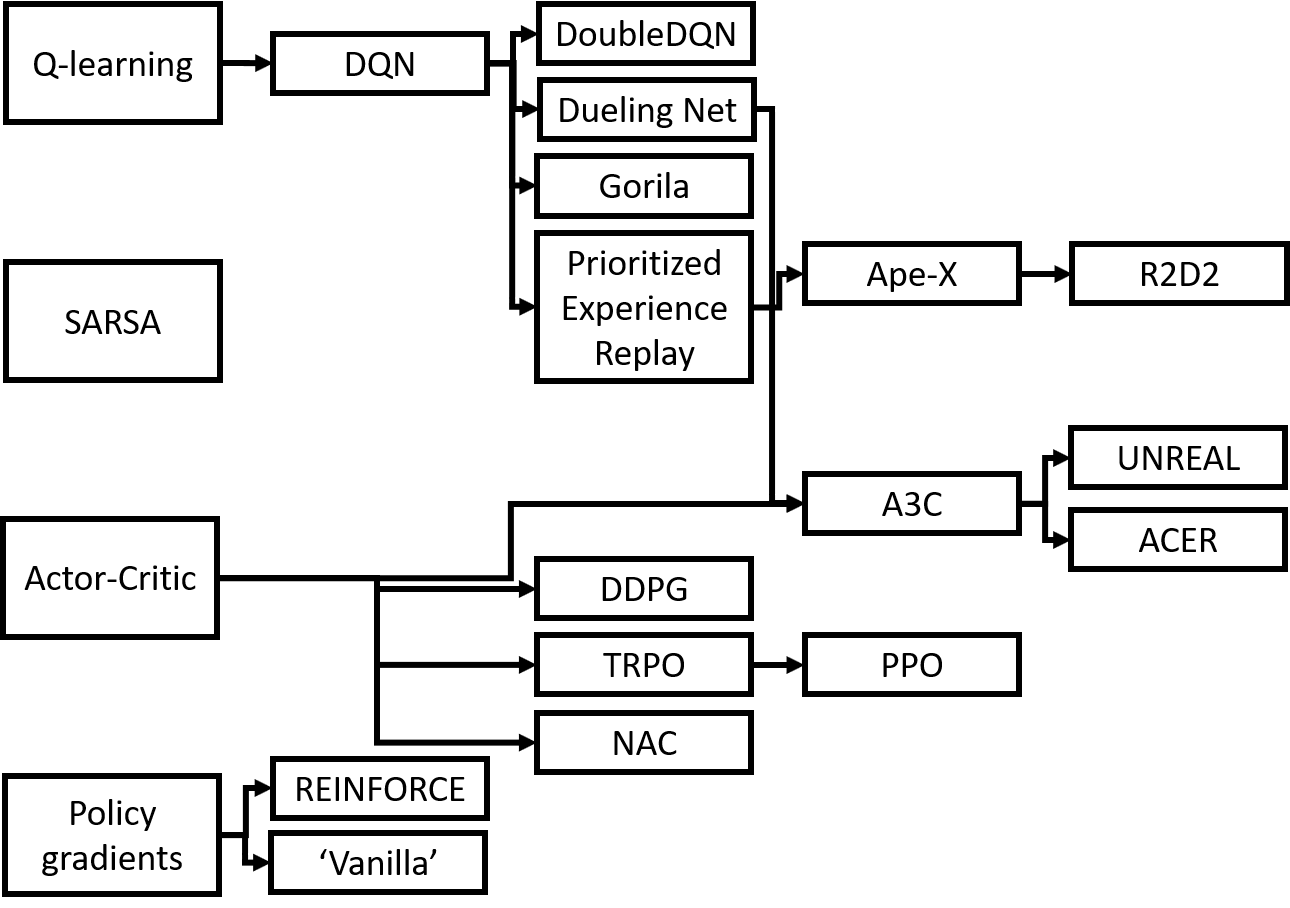 (引用元:https://qiita.com/shionhonda/items/ec05aade07b5bea78081)
(引用元:https://qiita.com/shionhonda/items/ec05aade07b5bea78081)
とても多く複雑であることがわかりますよね。
私が研究で扱っているのはこの中でもDoubleDQN(DDQN), DDPG, PPOの3つです。
元々は先輩から引き継いだ研究で、はじめはDDQNを実装してロボットの研究に使用していました。
DDQNは価値ベースのアルゴリズム、つまり現在の状況とあらかじめ定められた行動の選択に対しての価値を学習していくというものになります。
したがって、DDQNを用いたロボットの行動では決められた行動しか選択できなかったのです。
そこで私はロボットの行動自体を学習することのできる方策ベースのアルゴリズムDDPGとPPOを実装しました。
どちらのアルゴリズムでも学習はでいるのですが、報酬やネットワーク構成の調整をするだけで学習データは大きく変わります。
今回はPPOよりもDDPGのほうが目的地への到達確率はいい結果となりました。
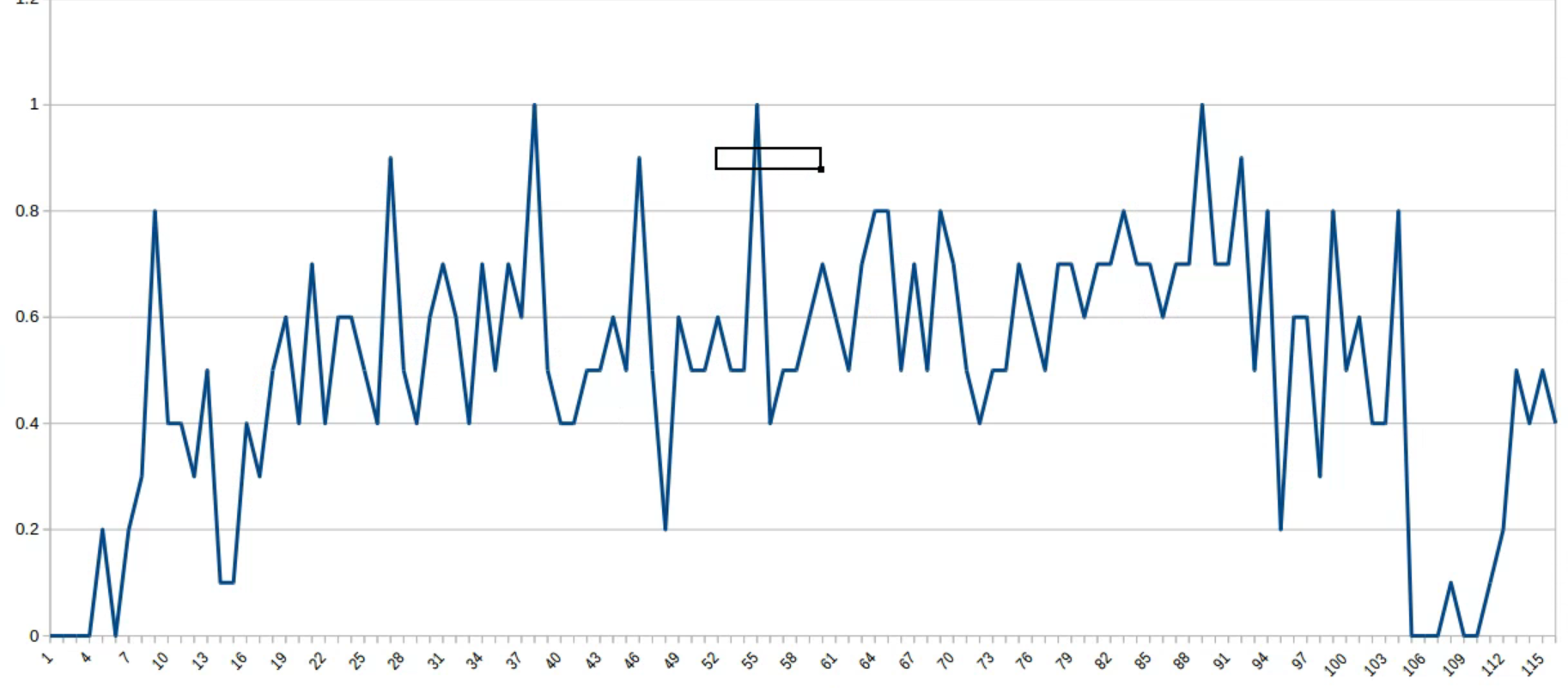 DDPGの目的地到達確率
DDPGの目的地到達確率
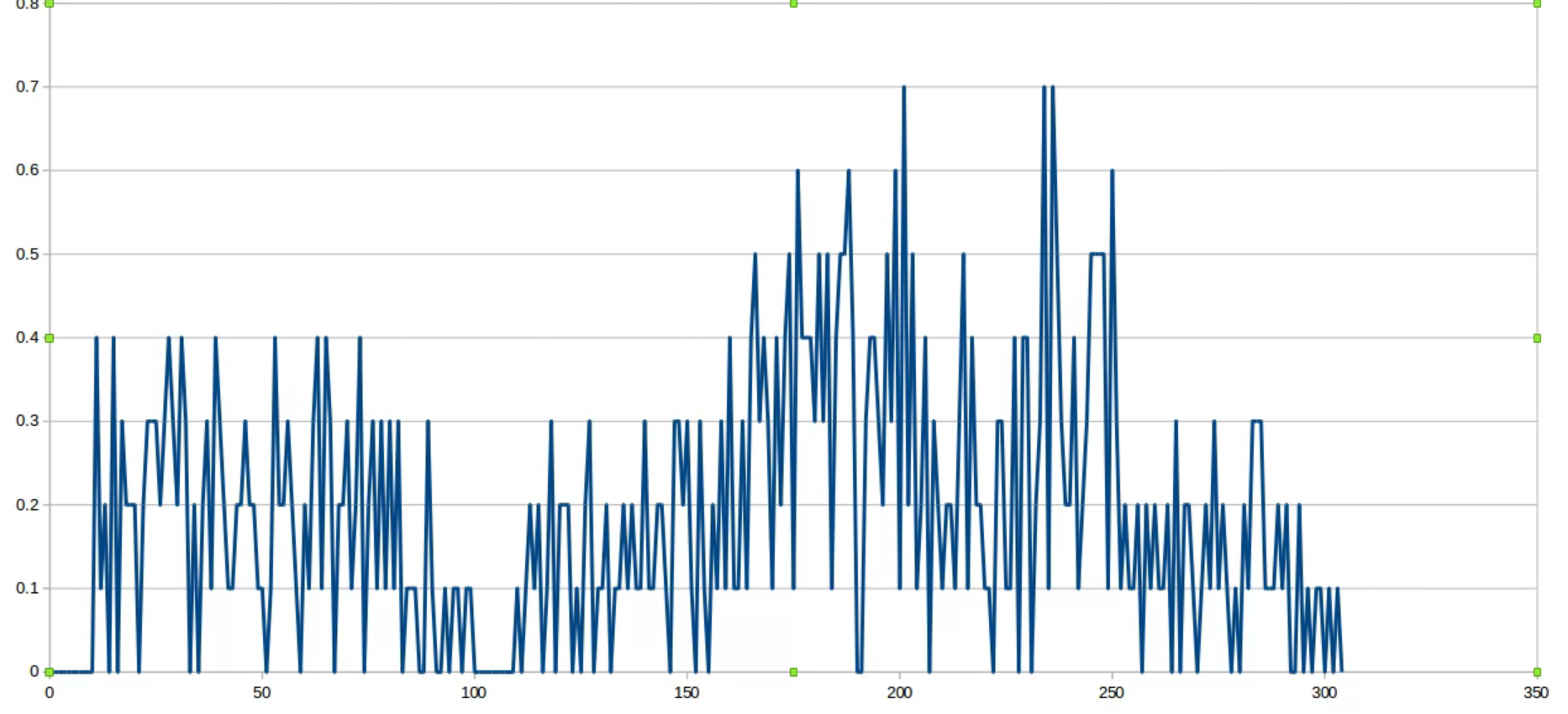 PPOの目的地到達確率
最近では研究とは別でデータ予測などで機械学習のアルゴリズムを勉強してます。
また、今年の秋に開催される機械学習の資格にも挑戦してみようと考えてみます。
興味がある人はいろいろな機械学習を学んでみてはいかがでしょうか。
PPOの目的地到達確率
最近では研究とは別でデータ予測などで機械学習のアルゴリズムを勉強してます。
また、今年の秋に開催される機械学習の資格にも挑戦してみようと考えてみます。
興味がある人はいろいろな機械学習を学んでみてはいかがでしょうか。