SIGNATEの機械学習コンペでブロンズメダル
2020年12月04日
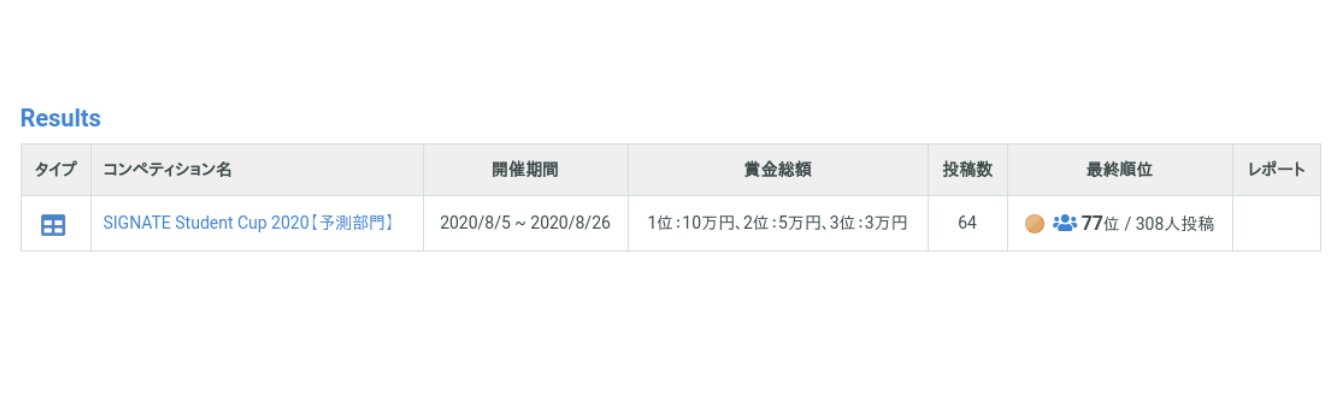
研究室の仲間と出た機械学習(NLP)コンペでブロンズメダルを取りました。
メンバー
- M2横山: データ分析の人
- M2末永: Web開発の人
- M1古谷: 眠れる獅子
77位/308人投稿というまあ大したことはない結果ですが素人にしては頑張ったのではないかと思います。
Slackであーだこーだ言いながら取り組んでいる様子。

コンペ詳細
ほぼ8月の全てを使ってSIGNATE Student Cup 2020【予測部門】に参加しました。学生コンペです。
タスクについては公式ページに書いてあることが全てですが、自然言語処理を使った分類問題です。求人の要件が書いてある文章からその求人がデータサイエンティスト、機械学習エンジニア、ソフトウェアエンジニア、コンサルタントのどれに該当するかを予測します。
write-up
基本的に全部ディープラーニングを使って予測していきます。以下は実際に自然言語処理による多クラステキスト分類問題をディープラーニングで解いてみた感想です。
- LightGBM等の勾配ブースティング手法を使うより一段上の結果が出やすい
- RNN(GRU, LSTM等)を使った手法は既に古くなりつつある
- Transformer(BERT等)を使うと高い精度が出やすい
- simpletransformersが使いやすい
- 学習済みモデルの検索はHuggingfaceが便利
- Google Colabを使うのが非常に便利
予測は(1) 複数の学習済みモデルを使って予測する、(2) 作ったモデルをブレンディング の2ステップで行いました。
(1) 学習済みモデルによる予測
BERT等を使った予測にはsimpletransformerを使いました。これはPyTorchをラップしたライブラリで、非常に簡単に学習済みモデルを扱うことができます。
基本的には学習済みモデルを変えたりパラメーターを変えたりして良さそうなモデルを作っていきます。
ベースとなる実装としては以下のフォーラムを参考にしました。
https://signate.jp/competitions/281/discussions/baseline-with-nlp-model
(なお機械学習初心者である私達はこのフォーラムを見るまでTransformerというものすら知らなかった)
他に使った手法は以下です。
- kfoldバリデーション
- 逆翻訳によるデータ水増し(フランス語ドイツ語スペイン語)
- 疑似ラベリング
実際に使ったコードは以下のgistです。人に見せられないくらいグチャグチャなので参考までにという感じです。
https://gist.github.com/asmsuechan/d820b89f6ed546942b63f0cc4e630e29
(2) ブレンディング
複数の予測結果を提出結果に基づいてブレンディングしました。ここで最終提出結果を作成します。
最終提出でどのモデルをブレンディングしたかは忘れてしまったのですが確かroberta-base-squad2やxlm-roberta-baseなど提出結果の上位を5つ程使ったように記憶しています。
反省点
- リーダーボードの暫定結果に気を取られすぎていた
- ブレンディング、スタッキングはもっとたくさんのモデルを使っても良さそう
- 逆翻訳を過信しすぎた。なくても良かった
- 類似コンテストを事前に調べるべきだった(今回はKaggleのJigsawコンペ)
感想
夏休みだったし論文落ち着いて就活くらいしかやることなかったので8月はほぼ毎日1日12時間以上ずっとメンバーとDiscordを繋いで機械学習をしていました。上位入賞は無理だったのですがブロンズメダルは取れたということで多少は報われた気がします。機械学習ほとんど未経験にしてはよくやったと思っています。
途中でGPUメモリ足りなくなってAWSの激烈高額ハイスペックGPUインスタンスを使っていたのですが2万円くらいかかりました。
機械学習コンペは競プロと違って時間的制約が非常にゆるいのでみんなでワイワイしながら取り組めるのがとても楽しいと思いました。